Частота шины fsb. Системные шины
Приветствую, дорогие друзья, знакомые, читатели, почитатели и прочие личности. Если Вы помните, то очень давно мы поднимали , но чисто в теоретическом разрезе, а после обещали сделать статью практическую.
Учитывая, что разгон таки штука довольно непростая и неоднозначная, то статей в этом цикле будет довольно приличное количество, а подзабросили мы его по одной простой причине, - тем для написания, помимо оного, существует бесконечное множество и везде успеть просто невозможно.
Сегодня мы рассмотрим самую базовую и типичную сторону разгона, но при всём при этом максимально затронем важнейшие и ключевые нюансы, т.е дадим понимание как оно работает на примере.
Приступим.
Разгон процессора в разрезе [на примере платы P5E Deluxe].
Собственно, можно сказать, что варианта разгона бывает два: с помощью программ или непосредственно из BIOS .
Программные методы мы сейчас не будем рассматривать по множествам причин, одна (и ключевая) из которых, - это отсутствие стабильной адекватной защиты системы (да и, в общем-то железа, если конечно не считать таковыми) в случае установки некорректных настроек находясь непосредственно в Windows . С разгоном же непосредственно из BIOS всё выглядит куда более разумно, а посему мы будем рассматривать именно этот вариант (к тому же, он позволяет задать большее количество настроек и добиться большей стабильности и производительности).
Вариантов BIOS "а существует довольно большое количество (а с приходом UEFI их стало и того больше), но основы и концепции разгона сохраняют свои принципы из года в год, т.е подход к нему не меняется, если не считать интерфейсы, местами названия настроек и ряд технологий этого самого разгона.
Я рассмотрю здесь пример на основе своей старенькой мат.платы (про которую я когда-то очень давно рассказывал ) и процессора Core Quad Q6600
. Последний, собственно, служит мне верой и правдой уже черт знает сколько лет (как и мат.плата) и разогнан мною изначально с 2,4 Ghz
до 3,6 Ghz
, что Вы можете увидеть на скриншоте из :
К слову, кому интересно, таки о том как выбирать столь хорошие и надежные мат.платы мы писали , а про процессоры . Я же перейду к непосредственно процессу разгона, предварительно напомнив следующее:
Предупреждение! Ахтунг! Аларм! Хехнде хох!
Всю ответственность за Ваши последующие (равно как и предыдущие) действия несёте только Вы. Автор лишь предоставляет информацию, пользоваться или нет которой, Вы решаете самостоятельно. Всё написанное проверено автором на личном примере (и неоднократно) и в разных конфигурациях, однако сие не гарантирует стабильную работу везде, равно как и не защищает Вас от возможных ошибок в ходе проделанных Вами действий, а так же любых последствий, что могут за ними наступить. Будьте осторожны и думайте головой.
Собственно, что нам нужно для успешного разгона? Да в общем-то ничего особенного не считая второго пункта:
- Во-первых, прежде всего, конечно же, компьютер со всем необходимым, т.е мат.платой, процессором и тп. Узнать, что за начинка у Вас стоит, Вы можете скачав вышеупомянутый ;
- Во-вторых, таки обязательно, - это хорошее охлаждение, ибо разгон прямым образом влияет на тепловыделение процессора и элементов материнской платы, т.е без хорошего обдува, в лучшем случае, разгон приведет к нестабильности работы или не будет иметь свой силы, а в худшем случае, что-нибудь таки попросту сгорит;
- В-третьих же, само собой, необходимы знания, дать которые призвана эта статья, из этого цикла, а так же весь сайт " ".
Касаемо охлаждения хочется отметить следующие статьи: " ", " ", а так же " ". Всё остальное можно найти вот так вот. Идем далее.
Так как всю необходимую теорию мы уже подробно разобрали в , то я сразу перейду к практической стороне вопроса. Заранее прошу прощения за качество фото, но монитор глянцевый, а на улице, не смотря на жалюзи, таки светло.
Вот так выглядит BIOS на борту моей мат.платы (попасть в BIOS , напомню, на стационарном компьютере, можно кнопочкой DEL на самой ранней стадии загрузки, т.е сразу после включения или перезапуска):

Здесь нас будет интересовать вкладка "Ai Tweaker ". В данном случае именно она отвечает за разгон и изначально выглядит как список параметров с выставленными напротив значениями "Auto ". В моём случае она выглядит уже вот так:


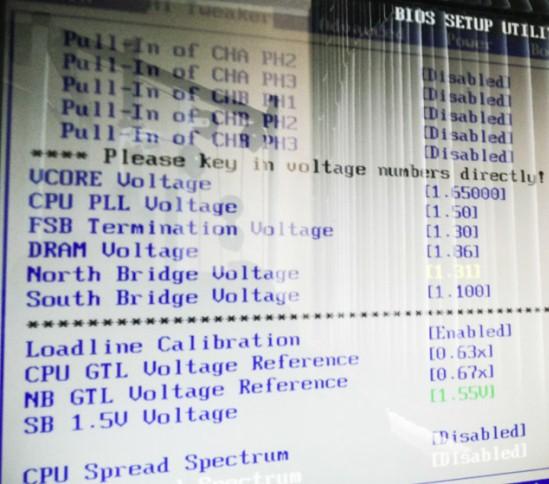
Здесь нас будут интересовать следующие параметры (сразу даю описание + моё значение с комментарием почему):
- Ai Оverclock Tuner
- занимается авторазгоном, якобы с умом.
В значении "Standard" всё работает как есть, в случае с "Overclock 5% , Overclock 10% , Overclock 20% , Overclock 30% " автоматически увеличивает частоты на соответствующий процент (причем без гарантий стабильности).Нас здесь интересует значение Manual , ибо оно позволит всё выставить нам ручками. Собственно, оно у меня и стоит. - Cpu Ratio Setting - задаёт множитель процессора. Можно выставить своё значение, при учете, что множитель процессора разблокирован.Я здесь выставил 9.0 , т.е максимально доступное из разблокированных значение множителя для моего процессора. Вам необходимо поступить аналогичным образом для Вашего процессора.
- FSB Frequency - задаёт частоту системной шины процессора, она же так называемая, базовая частота. Как Вы помните из теоретической статьи, конечная частота процессора получается из значения этой частоты, умноженного на множитель (как звучит! :)) процессора.Частота эта в нашем процессе является основной и именно её, в основном, мы и меняем, чтобы разогнать процессор. Значение подбирается опытным путём, методом комбинирования с другими параметрами до достижения момента, когда система работает стабильно и температурный режим Вас устраивает. В моём случае удалось взять планку в "400 x 9 = 3600 Mhz" . Были моменты, когда я брал 3,8 Ghz , но охлаждение попросту не справлялось в пиковых нагрузках с тепловыделением.
- FSB Strap to North Bridge
- параметр здесь есть ничто иное как набор предустановленных задержек, которые с точки зрения производителя оптимально соответствуют определенной частоте системной шины, для определенного диапазона рабочих частот чипсета. Здесь они задаются для северного моста.При установке значения FSB Strap
следует учитывать, что при меньшем значении устанавливаются меньшие задержки и увеличивается производительность, а при установке большего значения немного падает производительность, но повышается стабильность. Наиболее актуальна опция при разгоне для обеспечения стабильности при высокой частоте FSB
.Мне пришлось выбрать высокое значение, чтобы добиться стабильности. В моём случае это 400
.
- PCIE Frequency - указывает частоту для шины PCI Express . Разгон шины PCI Express обычно не практикуется: мизерный выигрыш в быстродействии не оправдывает возможные проблемы со стабильностью работы карт расширения, посему тут фиксируем стандартные 100 Mhz , дабы повысить стабильность.Т.е в моём случае, - здесь значине 100 . Его Вам тоже рекомендую.
- DRAM Frequency - позволяет задавать частоту оперативной памяти. Параметры для выбора меняются в зависимости от выставленной частоты FSB . Здесь стоит отметить, что часто разгон "упирается" именно в память, посему оптимальным считается задавать такую частоту FSB при которой здесь можно выбрать рабочую (стандартную) частоту Вашей оперативной памяти, если, конечно же, Вы не стремитесь разогнать именно память. Значение "Auto" часто вредно и не даёт должного результата с точки зрения стабильности.В моём случае выставлено "800" в соответствии с характеристиками оперативной памяти. В Вашем случае выставляйте как считаете нужным, но я рекомендую посмотреть Вашу стандартную частоту через CPU-Z и ставить её.
- DRAM Сommand Rate - ничто иное как задержка при обмене командами между контроллером памяти чипсета и памятью. Качественные модули памяти способны работать при задержке в 1 такт, но на практике это встречается редко и не всегда зависит именно от качества. Для стабильности рекомендуется выбирать 2T , для быстродействия 1T .Так как порог разгона взят большой, то я выбирал здесь 2T , ибо в других положениях полной стабильности добиться не удавалось.
- DRAM Timing Control - задаёт тайминги оперативной памяти. Как правило, если целью не стоит разгон оперативной памяти, то здесь мы оставляем параметр "Auto ". Если Вы катастрофически уперлись при разгоне в память и не пролезаете даже по частоте, то есть смысл попробовать немного завысить здесь значения вручную, отказавшись от автоматического параметра.В моём случае, - это "Auto" , т.к в память не упирался.
- DRAM Static Read Control - значение " Enabled" поднимает производительность контроллера памяти, а " Disabled" – снижает. Соответственно от этого зависит и стабильность.В моём случае "Disabled " (в целях повышения стабильности).
- Ai Сlock Twister - если брать в вольном переводе, то эта штука управляет количеством фаз доступа к памяти. Более высокое значение (Strong ) отвечает за повышение производительности, а более низкое (Light ) за стабильность.Я выбрал "Light " (в целях повышения стабильности).
- Ai Transaction Booster - здесь я вычитал много буржуйских форумов из которых многие данные противоречат друг другу, как и в русскоязычном сегменте. Где-то пишут, что эта штука позволяет ускорить или замедлить работу подсистемы памяти, корректируя параметры подтаймингов, влияющих в свою очередь на скорость работы контроллера памяти.Единственное, что адекватно удалось понять, что переключив сие в "Manual " мы можем настроить "Perfomance Level ", играясь со значением в цифре до того момента, когда не поймаем этап стабильности. У меня этот параметр застрял на 8- ке, ибо при других значениях система вела себя не стабильно.
- VCORE Voltage
- функция позволяет вручную указать напряжение питания ядра процессора. Не смотря на то, что именно эта радость часто позволяет повысить производительность (точнее сильнее разогнать процессор) путём повышения стабильности (без большего питания Вы вряд ли получите больший прирост и качество работы, что логично) при разгоне, - таки этот параметр крайне опасная игрушка в руках непрофессионала и может привести к выходу процессора из строя (если в BIOS
конечно не вшита функция защиты, как говорится, "от дурака" (с), как это есть в ), а посему не рекомендуется изменять значение питания процессора, более чем на 0.2
от штатного. Вообще говоря, этот параметр стоит увеличивать очень постепенно и очень маленькими шажками, покоряя всё новые и новые высоты производительности, до тех пор, пока не упретесь во что-то еще (память, температуры и тп), либо пока не достигните лимита в +0.2
.
Я бы не рекомендовал смотреть на моё значение, ибо оно является действительно завышенным, но играть в эти игры мне позволяет мощное охлаждение (фотография выше не считается, она устарела еще в 2008 -ом году), хороший БП, процессор и мат.плата. Будьте, в общем, осторожны, особенно на бюджетных конфигурациях. Моё значение 1,65 . Узнать родной вольтаж для Вашего процессора можно из документации или через CPU-Z . - CPU PPL Voltage - нечто из для стабильности, но у меня существует очень расплывчатое определение того, что это за вольтаж. Если всё работает как нужно, то лучше не трогать. Если нет, то можно повышать маленькими шажками.Моё значение, - 1.50 , ибо упёрся по стабильности, когда брал частоту 3,8 Ghz . Опять же, опирается оно на мой процессор.
- FSB Termination Voltage - иногда называется дополнительным напряжением питания процессора или напряжением питания системной шины. Его увеличение способно в некоторых случаях повысить разгонный потенциал процессора.Моё значение, - 1.30 . Опять же, стабильность при более высокой частоте.
- DRAM Voltage - позволяет вручную указать напряжение питания модулей памяти. Трогать имеет смысл в редких случаях для повышения стабильности и покорения более высоких частот при разгоне памяти или (редко) процессора.У меня чуть завышено, - 1.85 при родных 1.80 .
- North Bridge Voltage и Soulth bridge voltage - задаёт напряжение питания северного (North ) и южного (Soulth ) мостов соответственно. Повышать с осторожностью в целях повышения стабильности.У меня, - 1.31 и 1.1 . Всё в тех же целях.
- Loadline Calibration
- достаточно специфичная штука, позволяющая скомпенсировать проседаниенапряжения питания ядра при увеличении нагрузки на процессор.
В случае с разгоном всегда стоит выставлять "Enabled" , как Вы и видите у меня на скриншоте. - CPU Spread Spectrum
- включение этой опции способно уменьшить уровень электромагнитного излучения компьютера за счет худшей формы сигналов системной шины и центрального процессора. Естественно, не самая оптимальная форма сигналов способна снизить стабильность работы компьютера.Поскольку уменьшение уровня излучения незначительно и не оправдывает возможные проблемы с надежностью, опцию лучше выключить (Disabled
), особенно, если вы занимаетесь разгоном, т.е как в нашем случае.
- PСIE Spread Spectrum - аналогично тому, что выше, но только в случае с шиной PCI Express .Т.е, в нашем случае - "Disabled ".
Если говорить совсем упрощенно, то, в первую очередь, мы с Вами меняем множитель и частоту FSB , опираясь на ту конечную частоту процессора, что мы хотели бы получить. Далее сохраняем изменения и пробуем загрузится. Если всё получилось, то проверяем температуры, и компьютера вообще, после чего, собственно, либо оставляем всё как есть, либо пробуем взять новую частоту. Если же на новой частоте стабильности нет, т.е Windows не грузится или появляются синие экраны или что-то еще, то либо возвращаемся к прошлым значениям (или чуть утихомириваем свои аппетиты), либо подбираем все остальные значения ровно до тех пор, пока стабильность не будет достигнута.
Что касается различных типов BIOS , то где-то функции могут называться как-то иначе, но смысл несут они один и тот же, равно как и значения + принцип разгона остаются постоянными. В общем, при желании, разберетесь.
В двух словах как-то так. Остаётся лишь перейти к послесловию.
Послесловие.
Как видите из последних предложений, если задуматься, то быстрый разгон в общем-то не проблема (особенно при наличии хорошего охлаждения). Выставил два параметра, несколько перезагрузок и, - вуаля!, - заветные мегагерцы в кармане.
Тщательный же хороший разгон хотя бы на 50 %, т.е как в моём случае на 1200 Mhz плюсом к 2400 Mhz , требует некоего количества времени (в среднем это где-то 1-5 часов, в зависимости от удачливости и желаемого конечного результата), большую часть из которого отнимает шлифовка стабильности и температур, а так же пачку терпения, ибо больше всего в сим раздражает постоянная необходимость перезагрузок для сохранения и последующего тестирования новых параметров.
Подозреваю, что у желающих заняться сим процессом будет много вопросов (что логично), а посему, если они таки есть (равно как и дополнения, мысли, благодарности и прочее), то буду рад увидеть их в комментариях.
Оставайтесь с нами! ;)
PS : Крайне настоятельно не рекомендую заниматься разгоном ноутбуков.
Хотя процессоры Core i7 с интегрированным контроллером памяти уже анонсированы и доступны в магазинах, их присутствие на рынке остается и будет оставаться незначительным (по прогнозам самой же Intel), до выхода i5 еще есть время, так что пока сборщики будут продолжать готовить системы на базе процессоров предыдущей микроархитектуры. И конечно, задача оптимального подбора конфигурации при этом сохранит свою актуальность в применении к системам на базе Core 2. В данной статье мы в очередной раз рассмотрим несколько вариантов конфигураций памяти, чтобы понять, насколько быстрая и какого типа она нужна, чтобы раскрыть потенциал самых быстрых процессоров, но не переплачивать при этом понапрасну.
Вопрос о переплате абсолютно уместен, так как только «обычные» производители (вроде, скажем, Samsung и Hynix) продают соответствующие стандартам JEDEC модули, в характеристиках которых и указать-то нечего, кроме максимальной частоты, на которой они могут работать. Зато производители «элитной» памяти (Corsair, OCZ, GeIL и пр.) легко перекрывают заданные стандартом потолки и по частотам, и по напряжению питания (как правило, конечно, одновременно), за что вполне резонно хотят получить дополнительных денег. Более того, многие варианты платформ под процессоры Intel предполагают использование DDR3, а эта память, помимо того, что все еще дороже, чем DDR2, также провоцирует покупку «элитных» модулей, только теперь с совсем уж запредельными скоростными характеристиками. Кстати, такая память скорее всего не будет иметь перспектив при апгрейде, так как для процессоров на базе Nehalem есть официальная рекомендация производителя не поднимать напряжение модулей DDR3 выше 1,65 В.
Для исследования мы возьмем системные платы на двух топовых чипсетах: Intel X48 и NVIDIA nForce 790i Ultra SLI . Оба они обеспечивают максимальные возможные конфигурации для Core 2: полноценную поддержку PCI Express 2.0, поддержку всех стандартов памяти DDR3 (по крайней мере, при использовании модулей с расширением SPD - EPP 2.0 или XMP), поддержку частоты процессорной шины 400(1600) МГц. Сразу возникает вопрос: насколько актуальна последняя характеристика для обычных покупателей с учетом того факта, что до сих пор с частотой FSB 1600 МГц выпущен один-единственный процессор? Ответ: действительно, неактуальна, но исследование этого режима поможет нам выстроить более ясную общую картину, а кроме того, такой режим можно рассматривать как частный случай разгона, чтобы делать прикидки, какой памятью следует запасаться при желании разогнать процессор.
Исследование производительности
Тестовый стенд:
- Процессоры:
- Intel Core 2 Duo E6600 (2,4 ГГц, шина 1066 МГц)
- Intel Core 2 Duo E8200 (2,66 ГГц, шина 1333 МГц)
- Intel Core 2 Extreme QX9770 (3,2 ГГц, шина 1600 МГц)
- Материнские платы:
- MSI X48C Platinum (версия BIOS 7.0b6) на чипсете Intel X48
- XFX nForce 790i Ultra 3-Way SLI (версия BIOS P03) на чипсете NVIDIA nForce 790i Ultra SLI
- Память:
- 2 модуля по 1 ГБ Corsair CM2X1024-9136C5D (DDR2-1142)
- 2 модуля по 1 ГБ Corsair CM3X1024-1800С7DIN (DDR3-1800)
- Видеокарта: PowerColor ATI Radeon HD 3870, 512 МБ
- Жесткий диск: Seagate Barracuda 7200.7 (SATA), 7200 об/мин
Программное обеспечение:
- ОС и драйверы:
- Windows XP Professional SP2
- DirectX 9.0c
- Intel Chipset Drivers 8.3.1.1009
- NVIDIA Chipset Drivers 9.64
- ATI Catalyst 8.3
- Тестовые приложения:
- RMMA (RightMark Memory Analyzer) 3.8
- RMMT (RightMark Multi-Threaded Memory Test) 1.1
- 7-Zip 4.10b
- Doom 3 (v1.0.1282)
Предваряя тестирование
Оба примененных чипсета, как уже было сказано выше, рассчитаны на память типа DDR3. К счастью, на базе чипсета Intel выпущено достаточное количество системных плат, предполагающих использование DDR2 или комбинированных, как примененная нами модель MSI.
Какие же конфигурации мы будем проверять? Здесь надо сделать традиционное вынужденное отступление и пояснить, что скорости операций с памятью ограничены собственно частотой и таймингами работы памяти, а также характеристиками процессорной шины, поскольку именно ее пропускная способность может лимитировать максимальную скорость перекачки данных из памяти и обратно. Действительно, начиная с момента использования двухканального доступа к DDR, пропускная способность памяти не уступает ПС системной шины, а со времен внедрения DDR2 - и значительно превосходит ее (для частоты FSB 1066 МГц, например, ПС шины составляет ~8533 МБ/с, что соответствует ПС двухканальной DDR2-533).
Но достаточно ли будет установить в плату два модуля DDR2-533 одновременно с процессором с FSB 1066 МГц? Однозначности ответа мешает еще как минимум такой параметр, как тайминги памяти. Из общих соображений понятно, что чем выше частота работы микросхемы памяти, тем больше должны быть относительные (выраженные в количестве тактов) задержки доступа к ней (просто потому, что время такта сократится). Однако на практике иногда, с одной стороны, удается обеспечить сохранение таймингов при повышении частоты (за счет того, что абсолютная задержка доступа может точнее уложиться в заданное количество тактов), а с другой стороны, в зависимости от организации микросхем и прочих параметров, при снижении частоты относительная задержка уже не может быть уменьшена, так как достигла предела рабочих характеристик. Таким образом, скажем, система с FSB 1066 МГц и двумя модулями DDR2-533, работающими при CL=4, должна, по идее, показать производительность чуть ниже, чем та же система с двумя модулями DDR2-667, работающими при той же задержке CL=4.
В нашем исследовании мы постарались обеспечить некоторое сочетание различных частот FSB, а также частоты и таймингов памяти, дополняя или проверяя результаты на двух чипсетах.
Результаты тестов при FSB 1066 МГц
Первым установим на тестовые стенды процессор с частотой FSB 1066 МГц. Как мы уже указали выше, с точки зрения величины пропускной способности при этой частоте шины достаточно использовать двухканальную DDR2-533. Впрочем, мы не включили в тестирование такую конфигурацию памяти, потому что DDR2-533 на рынке уже практически не представлена, так что ее цена неадекватна ситуации. Модули DDR2-667 и DDR2-800 представлены гораздо шире, но нельзя уверенно сказать, что между ними есть определенная разница по цене. Тем не менее, конфигурацию с двухканальной DDR2-667 мы все-таки рассмотрим - хотя бы из исследовательского интереса.
Мы уже отмечали в прошлых статьях, что при работе в равных режимах чипсет NVIDIA немного опережает решения Intel, а в синтетических тестах это иногда бывает заметно особенно хорошо. Также DDR3 в нынешних системах, как правило, немного медленнее, чем DDR2 (при использовании одинаковых скоростных режимов и таймингов). В дальнейшем не будем уделять внимания этим вопросам, если только разница не проявится в интересующем нас аспекте сравнения конфигураций памяти.
Традиционно начнем с низкоуровневого исследования потенциала памяти при помощи разработанного нашими программистами теста .
По данной диаграмме хорошо заметно, что скорость системы растет во всех случаях при увеличении частоты памяти до 1066 МГц, даже если это сопровождается повышением таймингов - иногда явно непропорциональным (например, абсолютные величины задержек доступа у DDR3-1066@7-7-7-20-1T гораздо хуже, чем у DDR3-800@5-5-5-16-1T). И лишь повышение частоты памяти до 1333 МГц ничего не дает (или, по крайней мере, перекрывается эффектом от повышения таймингов на шаг).
Картина при изучении скорости записи в память абсолютно соответствует описанной в предыдущем случае.
Неудивительно, что и тест латентности чтения из памяти демонстрирует те же соотношения, хотя в данном случае DDR3-1333 все-таки сумела чуть обойти DDR3-1066 по времени случайного доступа.
Теперь проверим, не изменится ли картина при многопоточном доступе в память: возможно, два ядра в конкурирующем режиме сумеют более эффективно использовать пропускную способность шины? Для этой цели используем тест RMMT (RightMark Multi-Threaded Memory Test) из пакета RMMA. (Для операций каждому потоку выделим по 32 МБ, дистанцию предвыборки данных будем подбирать индивидуально, чтобы максимизировать результат.)
Очевидно, что величина цифр несколько изменилась (многопоточное чтение идет чуть быстрее, многопоточная запись - чуть медленнее), однако взаимное расположение участников - нет.
Что ж, теперь проверим полученные данные на паре реальных приложений, а заодно оценим разницу в актуальных величинах.
Вооруженные результатами синтетических тестов, мы и не ожидали иного расклада. Производительность при архивировании (группа реальных тестов, наиболее сильно зависящих от скорости подсистемы памяти) действительно увеличивается с поднятием частоты памяти до 1066 МГц, даже при непропорциональном увеличении таймингов. В то же время, использование DDR3-1333 видимых дивидендов не приносит, хотя практически не снижает производительность, если тайминги при этом не слишком «задираются».
Производительность в играх подчиняется тем же закономерностям - по крайней мере, в тех игровых режимах, где скорость ограничена именно процессором и памятью, а не видеокартой.
Посмотрим на абсолютные величины выигрыша. В 7-Zip применение наиболее быстрой (де-факто) конфигурации на Intel X48 (DDR2-1066@5-5-5-16-2T) ускоряет систему с FSB 1066 МГц на 6,5% относительно базовой (DDR2-667@4-4-4-12-2T). Это не так уж мало: разница примерно соответствует 0,5 множителя частоты процессора, то есть при прочих равных такое ускорение обеспечивает ту же разницу, что и покупка процессора на одну модель старше. В Doom 3 аналогичный эффект равен и вовсе +8,3%. Главный же вывод из данной группы тестов: применение более скоростной памяти, вопреки чисто теоретическим выкладкам, обеспечивает ускорение системы вплоть до применения DDR2/DDR3-1066. Случайно ли, что максимальная эффективная частота памяти совпадает с частотой FSB? Попробуем найти ответ в следующих разделах.
Результаты тестов при FSB 1333 МГц
Теперь установим на тестовые стенды процессор с частотой FSB 1333 МГц. Опять-таки, с точки зрения величины пропускной способности при этой частоте шины достаточно использовать двухканальную DDR2-667. Поскольку штатные варианты DDR2 не могут даже приблизиться к этой частоте FSB, сосредоточимся мы на DDR3.
Скорость чтения из памяти по-прежнему уверенно растет при повышении частоты ее работы вплоть до 1333 МГц, даже в тех случаях, когда тайминги повышаются непропорционально (CL7 у DDR3-1333 в сравнении с CL5 у DDR3-1066). А вот частота памяти 1600 МГц прироста производительности не дает, и снижение абсолютной величины таймингов не помогает.
Впрочем, по скорости записи в память сравнительные результаты получаются чуть иными, но лишь в последнем пункте: здесь есть прирост и от повышения частоты памяти до 1600 МГц.
Результаты теста латентности чтения ближе к теоретическим выкладкам по подсчету таймингов: здесь выигрыш имеют те режимы, которые обеспечивают меньшие значения таймингов в абсолютных величинах. В итоге память с большей частотой всегда выигрывает но лишь поскольку (и насколько) имеет тайминги пониже.
Многопоточное чтение по-прежнему идет чуть быстрее, а многопоточная запись - чуть медленнее, а результаты в той же степени соответствуют результатам при однопоточном доступе в память.
Вряд ли кого-нибудь удивит практическое подтверждение синтетических тестов; по большому счету, интрига заключалась только в вопросе, сумеет ли DDR3-1600 при более низких таймингах опередить DDR3-1333. Практика деликатно уклонилась от прямого ответа на этот вопрос, предоставив нам самостоятельно оценивать статистическую погрешность тестирования. Что ж вполне можно признать эти режимы равными по скорости.
Теперь конкретные цифры разницы в реальных приложениях. 7-Zip уверенно отдает предпочтение чипсету NVIDIA, так что у нас есть два варианта сравнения: Intel X48 с DDR3 в лучшем случае выигрывает около 5,5% относительно режима с DDR2-667@4-4-4-12-2T, а NVIDIA nForce 790i Ultra - примерно столько же, но в сравнении с самым медленным режимом DDR3. Если бы мы рассматривали неофициальные скоростные вариации DDR2 (а производители такие модули предлагают), то, очевидно, могли бы получить и больший прирост на Intel X48, так как DDR2 на нем работает быстрее, а частота памяти задается независимо от ее типа. В случае Doom 3 максимальный прирост (из возможных штатных) на X48 составил почти 7%, у чипсета NVIDIA он скромнее, но и минимальный режим более скоростной.
В этом разделе тестов мы подтверждаем вывод о пользе применения более скоростной памяти, и лишь верхнюю границу однозначно определить затрудняемся: 1333 МГц достаточно, но хоть падения скорости от покупки DDR3-1600 с нормальными таймингами можно не ожидать.
Результаты тестов при FSB 1600 МГц
Наконец, настал черед единственного в своем роде процессора с частотой FSB 1600 МГц. Штатные возможности контроллера памяти в чипсете Intel не дадут нам создать здесь достаточно интересную непрерывную цепь показателей, так что воспользуемся по полной программе гибкостью контроллера памяти у NVIDIA nForce 790i Ultra. Вообще, такая частота FSB ограничивает минимальную частоту памяти на уровне 1066 МГц (только в случае контроллеров Intel, конечно), то есть штатные модули DDR2 здесь использовать невозможно. Это означает, что наше сравнение из практической плоскости «оправдана ли покупка нестандартной, более дорогой памяти?» переходит в чисто теоретическое «какая нестандартная память лучше?». Впрочем, не будем забывать и о DDR3 - там эти частоты вполне стандартны.
Что ж, вполне привычная по предыдущим частям сравнения картина: скорость чтения из памяти растет при повышении частоты ее работы вплоть до 1600 МГц, но не дальше, и, опять же, увеличение таймингов не нарушает эту закономерность.
Та же картина и при записи, только здесь еще более подчеркнута бесполезность и даже вредность DDR3-1800.
Впрочем, DDR3-1800 берет реванш в тесте латентности чтения: как ни крути, а абсолютные величины таймингов в этом режиме ниже.
Как мы помним по результатам первого тестирования процессора QX9770 с двухканальной DDR2-800, максимальная скорость многопоточного чтения достигается при конкурентной работе двух потоков, выполняющихся на физически разных ядрах, а максимальная скорость многопоточной записи - при конкурентной работе двух потоков, выполняющихся на ядрах, относящихся к физически единому ядру (разделяющих общий кэш L2). Дополнив прежнюю конфигурацию тестовых стендов чипсетом NVIDIA и куда более скоростными модулями памяти, мы получили следующие интересные наблюдения:
- на NVIDIA nForce 790i Ultra SLI скорость чтения практически одинакова при работе двух потоков, выполняющихся на физически разных ядрах и на ядрах, относящихся к физически единому ядру (а четырехпоточное чтение существенно медленнее);
- скорость чтения с предвыборкой происходит на NVIDIA nForce 790i Ultra SLI существенно быстрее в случае чтения в два потока с ядер, относящихся к физически единому ядру (а четырехпоточный вариант вновь заметно медленнее остальных);
- зато максимальная скорость записи на NVIDIA nForce 790i Ultra SLI выше именно при работе двух потоков на физически разных ядрах, запись в 4 потока занимает промежуточное положение по скорости.
Для наших целей возьмем именно максимальные показатели, полученные, таким образом, при немного отличающихся условиях тестирования многопоточных чтения и записи.
В случае чипсета Intel преимущества от использования DDR3-1600 очевидны; у чипсета NVIDIA разница между разными режимами отнюдь не так впечатляет, но общий итог прежний: более быстрая (но не быстрее FSB) память дает некоторый выигрыш в скорости.
Тем важнее практическая проверка, и ее результаты не столь оптимистичны: различия между режимами с памятью разной частоты укладываются в 2-3%, что вряд ли можно считать серьезным стимулом для покупки топовых модулей памяти.
Таким образом, «полусинтетический» раздел тестов позволил нам подтвердить вывод о принципиальной пользе применения более скоростной памяти, с небольшим максимумом в районе DDR3-1600, но реально измеримого превосходства в производительности относительно базовой DDR3-1066 можно не ждать. Еще раз напомним, что этот вывод относится не только к крайне немногочисленным обладателям QX9770, но и ко всем оверклокерам, серьезно увеличивающим частоту FSB для разгона процессора.
Выводы
Здесь нам остается только свести воедино результаты, полученные при тестировании в трех группах конфигураций, и соотнести их с изначальным вопросом статьи.
Итак, в случае распространенных процессоров семейства Core 2 с частотой FSB 1066/1333 МГц, вопреки чисто теоретическим выкладкам, имеет некоторый смысл использовать двухканальную память, существенно превосходящую по пропускной способности штатную системную шину. Если взять за опорную точку конфигурацию с DDR2-667 (как наиболее дешевый из реально представленных на рынке вариантов), то применением быстрой DDR2 или DDR3 можно выиграть 6-7-8% в реальных приложениях. Еще раз повторим, что это не так уж мало: разница примерно соответствует 0,5 множителя частоты процессора, то есть при прочих равных такое ускорение обеспечивает ту же разницу, что и покупка процессора на одну модель старше. Но, конечно, на ускорение в разы рассчитывать не стóит.
Память при этом оптимально подбирать такую, которая способна работать «псевдосинхронно» с FSB (их опорные частоты должны совпадать), не слишком задирая при этом тайминги (в абсолютных величинах, конечно). Будет ли такая покупка оправдана по большому счету? Почти всегда нет, так как разница в стоимости модулей «оверклокерской» и «обычной» памяти легко может составлять несколько раз (давая выигрыш, напомним, на 6–8%) - хотя вывод, безусловно, будет зависеть и от стоимости системы в сборе. Однако будут и ситуации, когда такая покупка явится наиболее рациональным способом улучшения системы - например, при намерении купить топовый или околотоповый процессор в линейке.
Сделанные выводы останутся справедливыми и для варианта разгона процессора, но тогда платы на наиболее популярных чипсетах (Intel) просто физически не позволят использовать память с низкой частотой работы, а значит, опорная точка в любом случае сместится в сторону более дорогих и производительных модулей. В итоге выигрыш от применения, скажем, DDR3-1600/1800 будет существенно меньше (в районе 2-3%), хотя и разница в цене модулей памяти несколько нивелируется.
Здравствуйте, уважаемые читатели блога сайт. Очень часто на просторах интернета можно встретить много всякой компьютерной терминологии, в частности - такое понятие, как "Системная шина". Но мало кто знает, что именно означает этот компьютерный термин. Думаю, сегодняшняя статья поможет внести ясность.
Системная шина (магистраль) включает в себя шину данных, адреса и управления. По каждой их них передается своя информация: по шине данных - данные, адреса - соответственно, адрес (устройств и ячеек памяти), управления - управляющие сигналы для устройств. Но мы сейчас не будем углубляться в дебри теории организации архитектуры компьютера, оставим это студентам ВУЗов. Физически магистраль представлена в виде (контактов) на материнской плате.
Я не случайно на фотографии к этой статье указал на надпись "FSB". Дело в том, что за соединение процессора с чипсетом отвечает как раз шина FSB, которая расшифровывается как "Front-side bus" - то есть "передняя" или "системная". И, на который обычно ориентируются при разгоне процессора, например.
Существует несколько разновидностей шины FSB, например, на материнских платах с процессорами Intel шина FSB обычно имеет разновидность QPB, в которой данные передаются 4 раза за один такт. Если речь идет о процессорах AMD, то там данные передаются 2 раза за такт, а разновидность шины имеет название EV6. А в последних моделях CPU AMD, так и вовсе - нет FSB, ее роль выполняет новейшая HyperTransport.
Итак, между и центральным процессором данные передаются с частотой, превышающей частоту шины FSB в 4 раза. Почему только в 4 раза, см. абзац выше. Получается, если на коробке указано 1600 МГц (эффективная частота), в реальности частота будет составлять 400 МГц (фактическая). В дальнейшем, когда речь пойдет о разгоне процессора (в следующих статьях), вы узнаете, почему необходимо обращать внимание на этот параметр. А пока просто запомните, чем больше значение частоты, тем лучше.
Кстати, надпись "O.C." означает, буквально "разгон", это сокращение от англ. Overclock, то есть это предельно возможная частота системной шины, которую поддерживает материнская плата. Системная шина может спокойно функционировать и на частоте, существенно ниже той, что указана на упаковке, но никак не выше нее.
Вторым параметром, характеризующим системную шину, является. Это то количество информации (данных), которая она может пропустить через себя за одну секунду. Она измеряется в Бит/с. Пропускную способность можно самостоятельно рассчитать по очень простой формуле: частоту шины (FSB) * разрядность шины. Про первый множитель вы уже знаете, второй множитель соответствует разрядности процессора - помните, x64, x86(32)? Все современные процессоры уже имеют разрядность 64 бита.
Итак, подставляем наши данные в формулу, в итоге получается: 1600 * 64 = 102 400 МБит/с = 100 ГБит/с = 12,5 ГБайт/с. Такова пропускная способность магистрали между чипсетом и процессором, а точнее, между северным мостом и процессором. То есть системная, FSB, процессорная шины - все это синонимы . Все разъемы материнской платы - видеокарта, жесткий диск, оперативная память "общаются" между собой только через магистрали. Но FSB не единственная на материнской плате, хотя и самая главная, безусловно.

Как видно из рисунка, Front-side bus (самая жирная линия) по-сути соединяет только процессор и чипсет, а уже от чипсета идет несколько разных шин в других направлениях: PCI, видеоадаптера, ОЗУ, USB. И совсем не факт, что рабочие частоты этих подшин должны быть равны или кратны частоте FSB, нет, они могут быть абсолютно разные. Однако, в современных процессорах часто контроллер ОЗУ перемещается из северного моста в сам процессор, в таком случае получается, что отдельной магистрали ОЗУ как бы не существует, все данные между процессором и оперативной памятью передаются по FSB напрямую с частотой, равной частоте FSB.
Пока что это все, спасибо.
Процессорная (иначе - системная) шина, которую чаще всего называют FSB (Front Side Bus), представляет собой совокупность сигнальных линий, объединенных по своему назначению (данные, адреса, управление), которые имеют определенные электрические характеристики и протоколы передачи информации.
Таким образом, FSB выступает в качестве магистрального канала между процессором (или процессорами) и всеми остальными устройствами в компьютере: памятью, видеокартой, жестким диском и так далее.
Непосредственно к системной шине подключен только CPU, остальные устройства подсоединяются к ней через специальные контроллеры, сосредоточенные в основном в северном мосте набора системной логики (чипсета) материнской платы.
Хотя могут быть и исключения - так, в процессорах AMD семейства К8 контроллер памяти интегрирован непосредственно в процессор, обеспечивая, тем самым, гораздо более эффективный интерфейс память-CPU, чем решения от Intel, сохраняющие верность классическим канонам организации внешнего интерфейса процессора.
Основные параметры FSB некоторых процессоров:
Intel Pentium III: 100/133; AGTL+; 800/1066
Intel Pentium 4: 100/133/200; QPB; 3200/4266/6400
Intel Pentium D: 133/200; QPB; 4266/6400
Intel Pentium 4 EE: 200/266; QPB; 6400/8533
Intel Core: 133/166; QPB; 4266/5333
Intel Core 2: 200/266; QPB; 6400/8533
AMD Athlon: 100/133; EV6; 1600/2133
AMD Athlon XP: 133/166/200; EV6; 2133/2666/3200
AMD Sempron: 800; HyperTransport; 6400
AMD Athlon 64: 800/1000; HyperTransport; 6400/8000
* Процессор: частота FSB МГц; тип FSB; теоретическая пропускная способность FSB Мб/с
Процессоры компании Intel используют системную шину QPB (Quad Pumped Bus), передающую данные четыре раза за такт, тогда как системная шина EV6 процессоров AMD Athlon и Athlon XP передает данные два раза за такт (Double Data Rate).
В архитектуре AMD64, используемой компанией AMD в процессорах линеек Athlon 64/FX/Opteron, применен новый подход к организации интерфейса CPU - здесь вместо процессорной шины FSB и для сообщения с другими процессорами используется:
высокоскоростная последовательная (пакетная) шина HyperTransport, построенная по схеме Peer-to-Peer (точка-точка), обеспечивающая высокую скорость обмена данными при сравнительно низкой латентности.
Драйвер AMD Radeon Software Adrenalin Edition 19.9.2 Optional

Новая версия драйвера AMD Radeon Software Adrenalin Edition 19.9.2 Optional повышает производительность в игре «Borderlands 3» и добавляет поддержку технологии коррекции изображения Radeon Image Sharpening.
Накопительное обновление Windows 10 1903 KB4515384 (добавлено)

10 сентября 2019 г. Microsoft выпустила накопительное обновление для Windows 10 версии 1903 - KB4515384 с рядом улучшений безопасности и исправлением ошибки, которая нарушила работу Windows Search и вызвала высокую загрузку ЦП.
Драйвер Game Ready GeForce 436.30 WHQL

Компания NVIDIA выпустила пакет драйверов Game Ready GeForce 436.30 WHQL, который предназначен для оптимизации в играх: «Gears 5», «Borderlands 3» и «Call of Duty: Modern Warfare», «FIFA 20», «The Surge 2» и «Code Vein», исправляет ряд ошибок, замеченных в предыдущих релизах, и расширяет перечень дисплеев категории G-Sync Compatible.
Front Side Bus (FSB) - это магистральный канал, обеспечивающий соединение процессора и внутренних устройств: памяти, видеокарты, устройств хранения информации и т. п.
Наиболее часто можно встретить систему организации внешнего интерфейса процессора, которая предполагает, что параллельная мультиплексированная процессорная шина, носящая название FSB, соединяет процессор (порой два процессора, четыре или даже больше) и системный контроллер, который обеспечивает доступ к оперативной памяти и внешним устройствам. Этот системный контроллер обычно называется «северным мостом» (от англ. Northbridge). Он, наряду с «южным мостом» (от англ. Southbridge), входит в состав набора системной логики, который, однако, чаще фигурирует под названием «чипсет» (от англ. Chipset).
Northbridge
Северный мост начал именоваться именно так из-за своего расположения на материнской плате. Он представляет собой микрочип, визуально расположенный «под» процессором, однако в верхней части материнской платы, как бы в «северной» ее части.
Системный контроллер служит для передачи команд центрального процессора к оперативной памяти, и видеоконтроллеру (в случае встроенного видеоконтроллера, северный мост, производимый компанией Intel, именуется GMCH (от англ. Chipset Graphics and Memory Controller Hub), а также конвертацию этих команд в форму, необходимую для обращения к оперативной памяти. Порой, для увеличения потенциальной производительности системы, к северному мосту подключаются наиболее производительные периферийные устройства, например, видеокарты с шиной PCI Express, а менее производительные устройства (BIOS, устройства PCI, интерфейсы устройств хранения информации, ввода и т. п.) могут подключаться к так называемому южному мосту. Северный мост соединен с материнской платой посредством согласующего интерфейса, также контроллер соединяется шиной и с южным мостом.
Северным мостом определяются параметры (пропускная способность, частота, а также тип): системной шины, оперативной памяти (тип используемой памяти, а также ее максимальный объем), подключенного видеоконтроллера (режим работы, возможность использования SLI (от англ. Scalable Link Interface, что означает «масштабируемый интерфейс» и фактически означает возможность работы 2 (3 - 3-Way SLI, или даже 4 - Quad SLI) видеоадаптеров одновременно, что чрезвычайно повышает производительность видео).
В настоящее время в процессорах серии Core i-x с разъемом LGA 1156 северный мост встроен в процессор и связывается с ядрами по внутренней шине QPI со скоростью соединения 2.5^109 операций в секунду. Из факта поглощения процессором северного моста вытекает неактуальность использования шины FSB и внешней шины QPI в подобных системах.
Southbridge
Еще одним компонентом чипсета является функциональный контроллер ввода-вывода (от англ. I/O Controller Hub, ICH), так называемый южный мост, служащий для связи центрального процессора (через северный мост) с устройствами, не столь критичными к скорости взаимодействия:
Контроллеры PCI (X, E), прерываний, SMBus (I2C), LPC, IDE/SATA DMA, IRQ, ISA;
Super I/O: контроллер floppy-дисководов; контроллер LPT-порта; Контроллер COM-портов; MIDI, джойстик, инфракрасный порт и т.п.
Часы реального времени RTC (от англ. Real Time Clock);
BIOS (CMOS), вместе с энергонезависимыми системами обеспечения;
Системы энергообеспечения APM и ACPI;
Звуковой контроллер (AC97);
Может включать в себя контроллеры Ethernet, USB, RAID, FireWire и т. п.
Особенностью южного моста является его взаимодействие с внешними устройствами. Как следствие, он довольно чувствителен различным негативным факторам, влияющим на нормальную работу устройств (короткое замыкание, перегрев, деформация материнской платы и т. п.). Замена южного моста, как правило, составляет стоимость самой материнской платы, поэтому замена его нерациональна из-за ее высокой стоимости и обычно не проводится.
Шина BSB (от англ. Back Side Bus) служит для соединения центрального процессора с кэш-памятью второго уровня для процессоров, в которых используется двойная независимая шина DIB (от англ. Dual Independent Bus), которая также называется вторичным (или внешним) КЭШем (и носит обозначение L2-cache).
Компанией Intel была разработана системная шина QPB (от англ. Quad Pumped Bus), передающая 4 64-разрядных блока данных или 2 адреса за такт, тогда как пытавшаяся получить лицензию на системную шину GTL+ для создания своих новых процессоров, компания AMD вынуждена была при создании процессоров серии К7 лицензировать шину EV6 для процессоров AMD Athlon и Athlon XP передающую данные два раза за такт (Double Data Rate).
Данная шина оказалась значительно сложнее в производстве, чем предыдущие исполнения. Данное обстоятельство не могло не сказаться на серьезном увеличении количества транзисторов, используемых для реализации вышеуказанного принципа передачи данных, как для процессора, так и для самого чипсета.
DMI (от англ. Direct Media Interface) – шина, которая была разработана компанией Intel, для соединения южного и северного мостов материнской платы. Для разъема LGA 1156 со встроенным контроллером памяти (продукты Core i3, Core i5 и некоторые серии Core i7 (800, к примеру)), DMI соединяет процессор и чипсет PCH (от англ. Platform Controller Hub) по технологии CtC (от англ. Chip-to-Chip).
PCH является, по сути, аналогом южного моста, однако представляет из себя совершенно новый P55 Ibex Peak. Фактически, в новом решении сочетается расширенный функционал предыдущих версий южных мостов компании Intel, а также дополнительный контроллер PCI-e для периферии.
Первыми чипсетами, построенными с помощью технологии DMI, были устройства серии Intel i915, на основе сокета LGA 1156, получившие свое распространение с 2004 года.
Пропускная способность DMI составляет 2 Гбайт/с. Из-за столь невысоких значений, инженеры Intel пошли на революционное решение, встроив контроллер памяти, PCI-e и непосредственно интерфейс DMI в сам процессор.
HyperTransport
HyperTransport (ранее известная, как Lightning Data Transport) – технология последовательной/параллельной связи, разработанная с использованием технологии P2P (от англ. «point-to-point»), которая обеспечивает достаточно высокую скорость при низком уровне латентности (от англ. Low-latency responses), которая обеспечивает межпроцессорную связь, связь процессоров с сопроцессорами и процессоры с I/O Controller Hub. Имеет оригинальную схему на основе соединений, тоннелей, последовательного объединения нескольких тоннелей в цепь и мостов (для организации маршрутизации пакетов между цепями) для более простого масштабирования всей системы.
HyperTransport оптимизирует внутрисистемные связи заменой шин и мостов на их физическом уровне. Также тут используется DDR (от англ. Double Data Rate), что позволяет производить до 5.2x109 посылок в секунду с частотой синхронизации сигнала на уровне 2.6 гигагерц.
Версии HyperTransport:
|
Очередной шаг в совершенствовании научно-технического процесса был обозначен инженерами компании Intel созданием нового типа системной шины QPI (от англ. Quick Path Interconnect, ранее известной, как Common-System Interface, или CSI). Она заключается в интегрированном контроллере памяти и быстрой последовательной шины P2P для доступа к распределенной и разделяемой памяти.
Необходимость повышения скорости обработки и обмена данными диктует более жесткие требования к пропускной способности шины. С развитием технологии и характеристик процессоров нового поколения, использование FSB уже неактуально и в полной мере является наглядным изображением пресловутого эффекта «бутылочного горлышка». Результатом модернизации технологии FSB было создание шины нового поколения – QPI. Общая пропускная способность данного нового вида системной шины достигает невероятных (для предшественников) значений в 25.6 ГБ/с.
Первые процессоры, построенные на технологии использования системной шины QPI, поступили на рынок в начале 2008 года. Данная технология является прямым конкурентом консорциума, во главе с компанией AMD, выпустившей системную шину HyperTransport.
Название микроструктуры процессорного ряда компании Intel - Nehalem произошло от названия небольшого города в США неподалеку от головного офиса компании Intel в г. Санта-Клара (основанного в 18 веке) в Калифорнии. Nehalem является продолжением процесса модернизации модельного ряда архитектур Intel x86. Свое продолжение в 2010 году QPI получила в процессоре серии Itanium 9300, получив кодовое имя Tukwila, что является большим шагом вперед для систем, построенных на базе Itanium. Вместе с QuickPath в процессоре используется встроенный контроллер памяти, и интерфейс памяти прямо использует интерфейс QPI для взаимодействия с другими процессорами и I/OCH. Именно в этих продуктах наиболее типичным решением и стала системная шина QPI, что делает вероятной возможность использования одного чипсета процессорами Tukwila и Nehalem.
Каждое ядро процессора содержит интегрированный контроллер памяти и скоростное соединение для подключения иных компонентов. Данная структура служит для обеспечения следующих аспектов:
Огромной производительности и удобства работы с памятью;
Динамически изменяемой полосы эффективного пропускания при связи процессора с иными компонентами системы;
Значительного увеличения характеристик RAS (от англ. Reliability, Availability, Serviceability, что дословно означает «надежность, доступность и обслуживаемость») - достигается для достижения наилучшего баланса между ценой, производительностью и энергоэффективностью.
Чипсеты с разъемом LGA 1366 используют шину DMI для связи между северным мостом и южным мостом. А процессоры для сокета LGA 1156 вообще не имеют внешнего интерфейса QuickPath, т.к. чипсеты для данного сокета взаимодействуют с однопроцессорными конфигурациями, а функционал северного моста же напрямую встроен в сам процессор, что заставляет использовать шину DMI для связи процессора с аналогом южного моста. Однако, встроенная шина QPI используется в процессорах сокета LGA 1156 для связи ядер и встроенного контроллера PCI-e внутри самого процессора.
Данные, передаваемые в виде датаграмм (пакетов) в системной шине QPI передаются по паре односторонних каналов, каждый из которых состоит из 20 пар проводов. Общая ширина канала составляет 20 бит, при этом 16 бит служат для передачи исключительно данных (полезной нагрузки). Максимальная пропускная способность одного канала варьируется от 4.8^109 до 6.4^109 транзакций в секунду, следовательно, общая максимальная пропускная способность одного соединения приближается к значениям от 19.2 до 25.6 ГБ/с в двух направлениях, что составляет, соответственно, от 9.6 до 12.8 ГБ/с в каждую сторону.
В настоящее время системную шину QPI используют, в основном, для серверных решений. Связано это обстоятельство с тем, что QPI приобретает максимальную эффективность (и КПД) именно в загруженности пересылкой данных в оба направления, как в случае с многосокетными рабочими станциями или, собственно, серверами.
Как показывают тесты, для пользовательских машин использовать решения на основе QPI нецелесообразно, так как даже намеренное снижение пропускной способности QPI в 2 раза никоим образом не влияет на получаемые результаты в тестах, даже при условии использования связки из 3 наиболее производительных графических адаптеров.
PCI (от англ. Peripheral Component Interconnect bus) – шина для соединения материнской платы с периферийными устройствами различного рода.
Начало PCI было положено в начале 1992 года компанией Intel (для замены шины VLB (от англ. Vesa Local Bus)), которая допустила полноценное использование возможностей процессоров 486, Pentium и Pentium Pro, при этом стандарт шины с самого начала был открыт, что гарантировало возможность создания устройств для шины PCI без обязательства лицензирования.
В 1993 году в ходе маркетинговой политики по продвижению PCI на рынке вышла PCI 2.0. В 1995 году данная модель модифицировалась до версии PCI 2.1.
PCI имела реальную тактовую частоту на уровне 33 МГц, тактовой частотой для версии 2.1 стало значение в 66 МГц, что позволило повысить скорость передачи данных до 533 Мбайт/с. Вместе с тем, и в операционных системах (Windows 95, к примеру) уже была предусмотрена поддержка шины PCI 2.1, которая стала настолько популярной, что вскоре была использована при создании платформ процессоров Alpha, MIPS, PowerPC, SPARC и т.д.
Однако, ничего не стоит на месте, включая научно-технический процесс, поэтому в связи с разработкой шины PCI Express, AGP и PCI практически не используются в решениях высшего ценового диапазона.
PCI Express
PCI Express получила свое кодовое название 3GIO (от англ. 3rd Generation I/O) – компьютерная шина, использующая последовательную передачу данных, обеспечиваемую высокопроизводительным физическим протоколом на основе программной модели шины PCI.
В связи с тем, что использование параллельной передачи данных, при попытке увеличить производительность, будет означать физическое ее расширение, последовательная передача данных обладает возможностью масштабирования (1x, 2x, 4x, 8x, 16x и 32x) а, значит, более приоритетна в разработке. Топология PCI Express, в общем случае, представляет собой звезду со взаимодействием между собой устройств через среду, образованную коммутаторами, с прямой связью каждого устройства соединением P2P.
Очередными отличительными особенностями PCI Express являются:
Возможность горячей замены карт;
Последовательность;
Спецификация;
Возможность создания виртуальных каналов, гарантирования полосы пропускания и количество времени отклика, а также сбора статистики QoS (от англ. Quality of Service)
Возможность влиять на энергопотребление оборудования ASMP (от англ. Active State Power Management) – перевод устройства в режим уменьшенного энергопотребления в случае его простоя в течение конкретного (задаваемого программно) интервала времени;
Контроль целостности информации и структуры данных, предназначенных для передачи – алгоритм Data Link прикрепляет к пакету данных (в передаче) контрольную сумму последовательности и ее номер, что позволяет обнаруживать все одиночные и двойные ошибки, а также ошибки в нечетном числе бит – CRC (от англ. Cyclic Redundancy Check).
В отличие от PCI (использование подключения к общей 32-разрядной параллельной двунаправленной шине), PCI Express использует двунаправленное последовательной соединение P2P, а соединение между двумя устройствами состоит из 1 (2, 4, 8, 16, 32) двунаправленных линий. На электрическом уровне каждое соединение способно подключаться к PCI Express всего лишь 4 проводниками.
Преимущества подобного решения налицо:
Устройство корректно работает в таком же слоте, или большей пропускной способности;
Корректная работа слота возможна даже при использовании не всех линий (однако в таком случае необходимо подключение и заземление всех проводников питания);
Физическая составляющая слота не позволит допустить некорректную работу системы, в случае попытки вставить устройство в слот с меньшей пропускной способностью, дифференциацией размеров слотов x1 (x2, x4, x8, x16, x32).
Чтобы высчитать пропускную способность PCI Express, нужно учесть битрейт, дуплексность связи и процент (отношение) эффективного количества «полезной нагрузки» бит к общему количеству (в PCI Express 1.0 и 2.x это отношение выглядело, как 8 бит информации / 10 бит служебных данных). Перемножая все три значения, получим скорость передачи данных. Так общая пропускная способность шины PCI Express 3.0 достигает 1 Гбайт/с для каждой линии при сигнальной скорости передачи данных в 8 GT/s (для 2.0 этот показатель был равен 5 GT/s, а для 1.0 – вообще 2.5 GT/s). А для планируемого к стандартизации и спецификации к 2014-2015 гг. стандарта 4.0 планируется удвоить показатель сигнальной скорости до 16 GT/s или даже более, что будет, по-меньшей мере, в 2 раза быстрее PCI Express 3.0
Заключение.
В настоящее время развитие технологий дает потребителям возможность выбирать технологию себе по вкусу из огромного количества вариантов. Решение различного рода задач потребителей задает необходимость определяться с наилучшим соотношением «цена-качество-целесообразность». К примеру: обыватель не замечает разницы в производительности между системами, построенных на базе сокета LGA 1366 (используется системная шина QPI) и сокета LGA 1156(1155) (используется системная шина DMI) в силу достаточности технологии, связанной с LGA 1156 и отсутствием задач, для которых ресурс данной системы был бы недостаточен. Лишь настоящие ценители и коллекционеры не откажут себе в радости приобретения компьютера, ресурс которого не будет использован и на 50%. Для потребителей-корпораций и крупных фирм нередко уже недостаточно производительности шины DMI.
Разрыв в разнице задач растет соответственно уровню потребителя. Кто знает, какие технологии используются в суперкомпьютерах мировых держав, однако ясно одно: именно эти технологии мы и будем использовать в ближайшем будущем.



